本記事では、PythonでExcel のMID、LEFT、RIGHT関数の操作を行う方法をご紹介します。
Pythonの実行環境
今回は、以下の実行環境でプログラムを実行しています。
・Python 3.7.6
・Jupyterlab 1.2.6
・Pandas:1.1.2
テストデータは、次のような予算管理表を使います。
ファイル名は「テストデータ.xlsx」で、シート名は「予算管理表」です。
■予算管理表


本記事で、今回利用するライブラリはPandasです。
import pandas as pd
※本記事では、Pythonのコードの下のコメントアウトは、出力結果を示しています。
PythonでExcelのMID、LEFT、RIGHT関数の操作を行う方法
Excelで文字列を分解するときにMID、LEFT、RIGHT関数を使います。
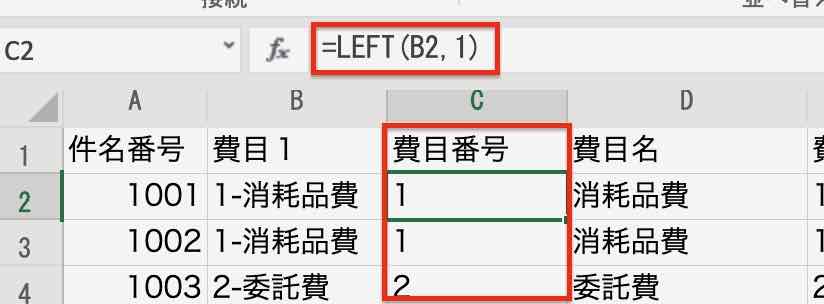
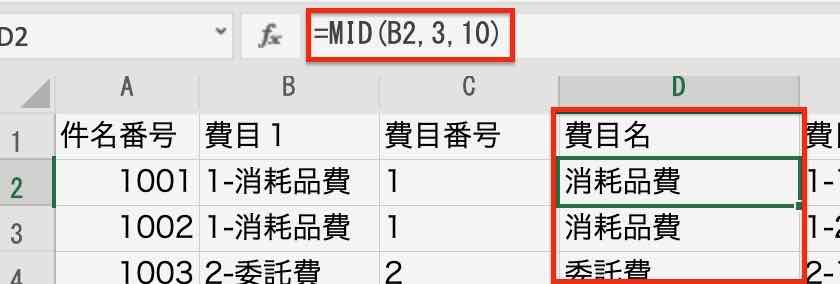
例えば、Excelで「費目1」列を番号と和名に分けたい時は、こんな感じでやっているでしょう。


まずはテストデータを読み込み、予算管理表をdfとします。
df = pd.read_excel('テストデータ.xlsx', sheet_name = '予算管理表')
そして、Excelと同様に「費目番号」列と、「費目名」列を追加します。
このとき、str[]を使って対象の列の文字列をスライスして抽出します。
「費目番号」列は、最初から1字目までを
「費目名」列は、2字目から最後までを
Pythonのコードでは次のように書けます。
df['費目番号'] = df['費目1'].str[:1]
df['費目名'] = df['費目1'].str[2:]
実際の結果は、次の通り、「費目番号」列と「費目名」列が追加されていることが分かります。
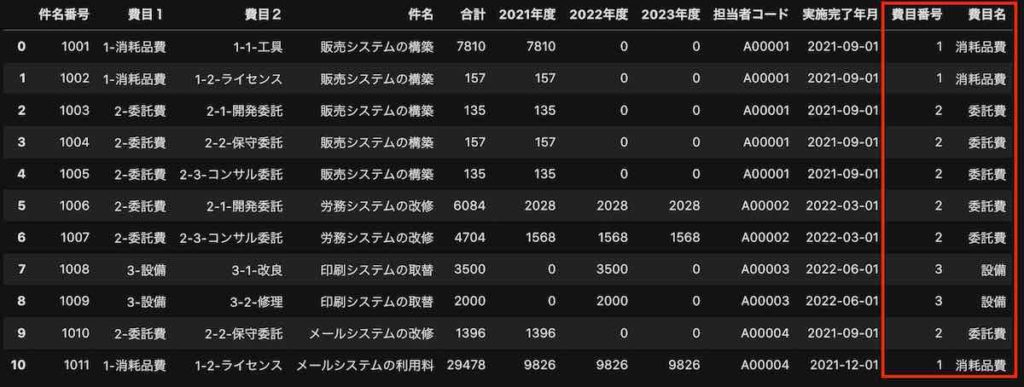

Pythonで必ず一番最後の列から追加になります。
Pythonでデータを扱う際は、列の並びはそこまで気にする必要がありません。
このように、str[]を使ってスライスで切り取る位置を指定すれば、ExcelのMID、LEFT、RIGHT関数の操作が簡単にできるのです。
【応用】PythonでExcelのMID、LEFT、RIGHT関数の操作を行う方法
上で紹介したPythonの書き方は、シンプルで簡単ですが、他にも応用的な書き方があります。
次のように、apply関数とlambda関数を組み合わせた書き方です。
※apply関数とlambda関数の使い方は、他のネット記事に分かりやすいものがたくさんありますので、そちらを参照ください。
df['費目番号'] = df['費目1'].apply(lambda x: str(x)[0:1])
df['費目名'] = df['費目1'].apply(lambda x: str(x)[2:])
結果は、上と同じになります。
どうして敢えて難しく書くのか?って思いますよね。
それは、文字列の操作を拡張するためです。
本記事の例では、文字列をある部分を取り出す(スライス)するだけですが、apply関数とlambda関数を使うことで、文字列の結合、条件に応じた加工、数値の計算などができるのです。
lambda関数の中身を変更すれば、ある程度自由に自分のやりたい処理が実現できると思います。
ぜひぜひapply関数とlambda関数のこの書き方(型)だけでも覚えておけば損はありません。
以上、PythonでExcelのMID、LEFT、RIGHT関数の操作を行う方法を応用的な書き方も含めて説明してきました。
最後まで読んでいただき、ありがとうございました。