本記事では、PythonでExcelの空欄・空白セルを判定し、欠損値の処理(除外、補完、符号化)をする方法をご紹介します。
Pythonの実行環境
今回は、以下の実行環境でプログラムを実行しています。
・Python 3.7.6
・Jupyterlab 1.2.6
・Pandas:1.1.2
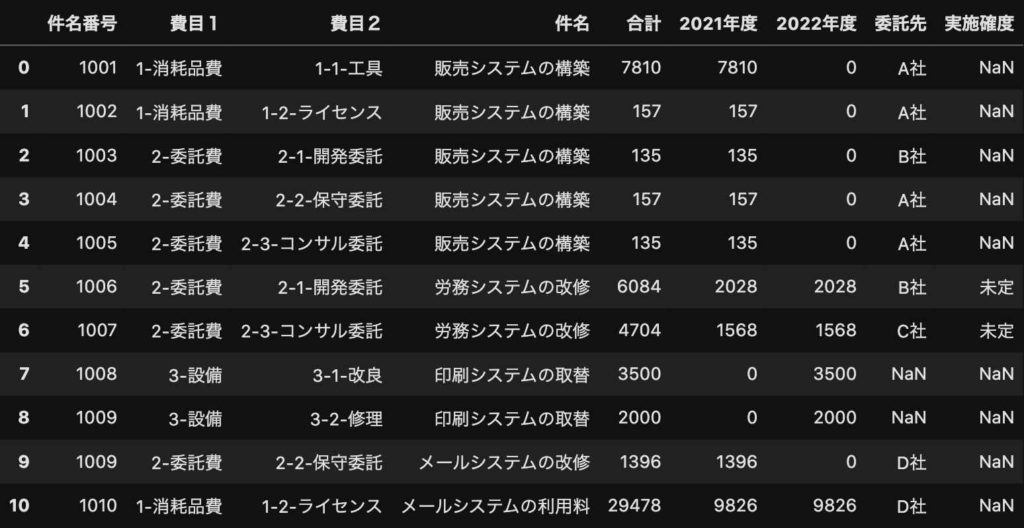
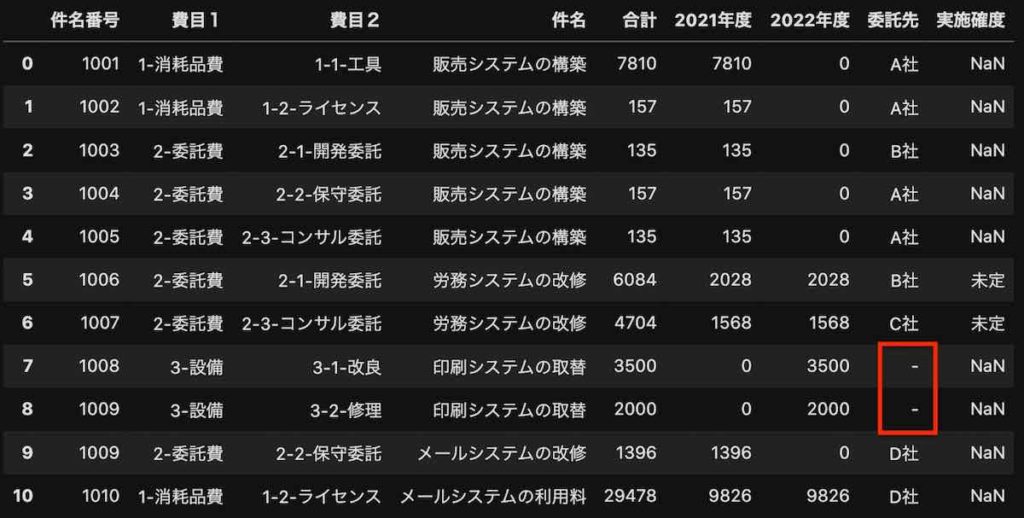
テストデータは、次のような予算管理表を使います。
ファイル名は「テストデータ.xlsx」で、シート名は「予算管理表」です。
■予算管理表
「委託先」列、「実施確度」列で空白があるテストデータを使います。


本記事で、利用するライブラリはPandasです。
そして、テストデータの予算管理表をdfとして読み込んでおきます。
import pandas as pd
df = pd.read_excel('テストデータ.xlsx', sheet_name = '予算管理表')
※本記事では、Pythonのコードの下のコメントアウトは、出力結果を示しています。
PythonでExcelの空欄・空白セルを判定する方法
Pythonでは、上の空白セルのある表を読み込むと次のようになります。
空白セルは、NaNになるのです。

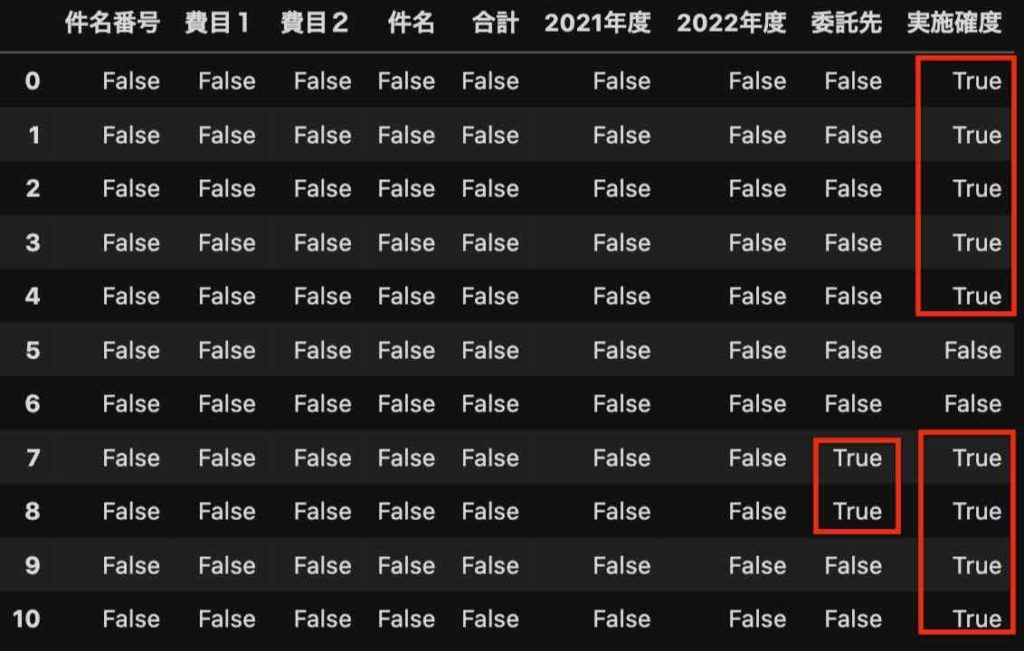
この中で、空白のセル(NaN)の判定をしたい時は、isnull()を使います。
df.isnull()
結果は、次のように、NaNの所がTrue、値が入っている所がFalseとなります。

isnull()とsum()と組み合わせて使うことで、列ごとにNaNの数を把握できます。
df.isnull().sum()
#件名番号 0
#費目1 0
#費目2 0
#件名 0
#合計 0
#2021年度 0
#2022年度 0
#委託先 2
#実施確度 9
PythonでExcelの空欄・空白セル(欠損値)を除外する方法
ここでは、欠損値の処理として次の方法をご紹介します。
・表全体で欠損値が1つでもある「行」を削除する
・表全体で欠損値が1つでもある「列」を削除する
・「特定の列で」欠損値が1つでもある行を削除する
上の3つは、どれもdropna()という欠損値除外のための関数を用います。
表全体で欠損値が1つでもある「行」を削除する
まず1つ目は、引数にhow='any'をしてします。
これは1つでも欠損値があると削除するという意味です。
df.dropna(how='any')
この結果は、次のようなります。実施確度がNaNとなっているレコードが除外されている。


表全体で欠損値が1つでもある「列」を削除する
これは、上のコードのdropna()にaxis=1を追加することで実現できます。
df.dropna(how='any', axis=1)
NaNを含む列が削除されます。今回の例だと、「委託先」列と、「実施確度」の列が削除されています。


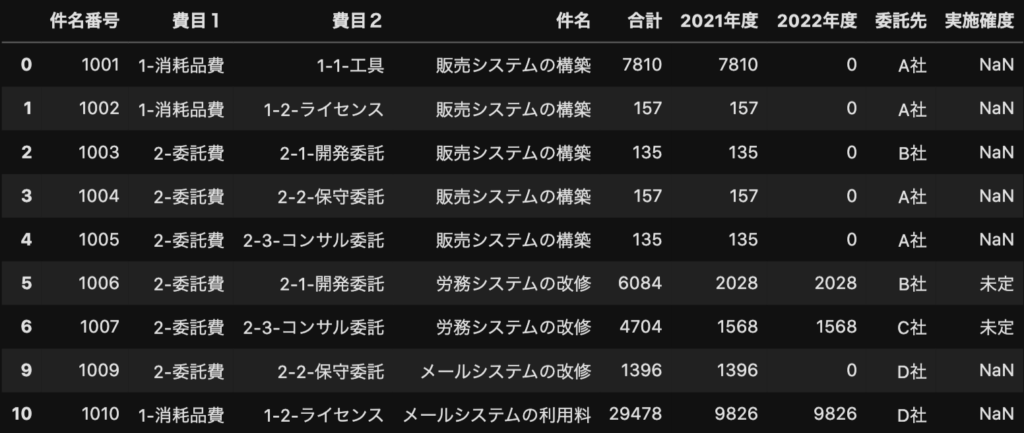
「特定の列で」欠損値が1つでもある行を削除する
上の2つは、表全体で欠損値(NaN)を判定し、行または列を削除してました。
次は、ある列内の欠損値(NaN)を探し、該当する行を削除します。
subsetという引数に対象の列を指定して、次のように書きます。
df.dropna(subset=['委託先'], how='any')
「委託先」列の欠損値が除外され、「実施確度」列のNaNは、何も影響してません。

PythonでExcelの空欄・空白セル(欠損値)を補完する方法
次は、欠損値を除外ではなく、欠損値を何かしらの値で補完する方法をご紹介します。
fillna()を使うと、欠損値(NaN)を好きな文字列に変換することができます。
今回は、「委託先」列の欠損値をハイフン(-)で埋めてみます。
df['委託先'].fillna('-')
fillna()の引数で、変換後の文字列を指定します。

このように、欠損値を任意の文字列に変換することのメリットを1つ紹介します。
それは、ピボットテーブルのインデックスとして使えるようになることです。
ピボットテーブルの作り方は、次の記事を参考にしてください。
参考Python/Pandasでピボットテーブルを作る方法
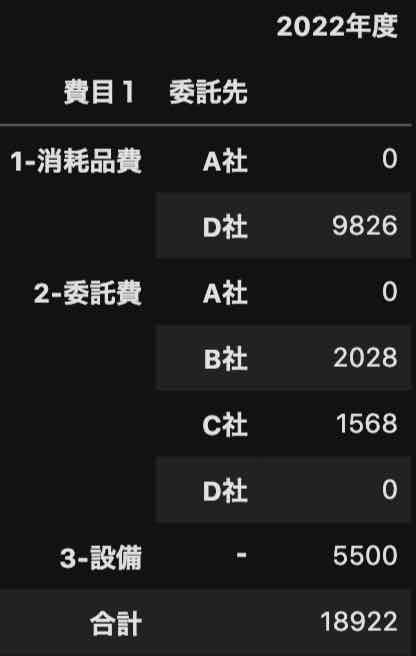
今回のピボットテーブルは、次のように記載します。
df.pivot_table(values=['2022年度'],
index=['費目1', '委託先'],
aggfunc='sum',
margins=True, margins_name='合計')
欠損値を補完することで、インデックス列として、値を集計できるようになります。
要注意:欠損値があると除外されるため、合計がズレてしまいます。

PythonでExcelの空欄・空白セルをフラグ/符号化する方法
最後に、空白とそれ以外のセルを識別するために、フラグ/符号化する方法をご紹介します。
テストデータの例だと、「実現確度」列で '未定' とそれ以外を区別するために、
'未定' → 0
それ以外 → 1
とするようなフラグ/符号列を作るということです。
これは、値の内容や大小ではなく、値が入っていることに意味がある場合によく使います。
Pythonでは、isnull()、apply()、lambdaを組み合わせて次のように書きます。
df['実施確度フラグ'] = df['実施確度'].isnull().apply(lambda x : '1' if x else '0')
これは、NaNの場合はif条件がTrueになり'1'で、NaN以外は、'0'になる「実施確度フラグ」という列を作っています。
結果は、次のようになります。


後工程でデータ分析、機械学習をする場合は、このようなフラグ/符号化した列も特徴量となり得るので重要となります。
以上、Pythonで空欄・空白セルを判定し、欠損値の処理(除外、補完、フラグ立て)をする方法を説明してきました。
最後まで読んでいただき、ありがとうございました。