本記事では、PythonでExcel のVLOOKUP関数の操作を行う方法をご紹介します。
Pythonの実行環境
今回は、以下の実行環境でプログラムを実行しています。
・Python 3.7.6
・Jupyterlab 1.2.6
・Pandas:1.1.2
テストデータは、次のような予算管理表を使います。
ファイル名は「テストデータ.xlsx」で、シート名は「予算管理表」と「担当者マスタ」です。
■予算管理表
レコード数:11、列数:10


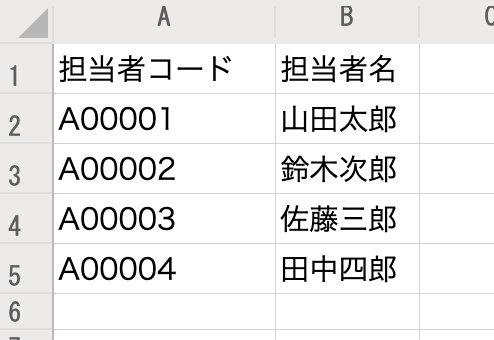
■担当者マスタ

本記事で、今回利用するライブラリはPandasです。
import pandas as pd
※本記事では、Pythonのコードの下のコメントアウトは、出力結果を示しています。
PythonでExcelのVLOOKUP関数の操作を行う方法
今回の例だと、Excelだと、'担当者コード'の列で次のようにvlookup関数を使えるますよね。


まずは、2つのシートを読み込みます。予算管理表をdf、担当者マスタをdf_userとします。
df = pd.read_excel('テストデータ.xlsx', sheet_name = '予算管理表')
df_user = pd.read_excel('テストデータ.xlsx', sheet_name = '担当者マスタ')
次に、読み込んだ2つの表を次のように結合します。
df = df.merge(df_user, on='担当者コード', how='left')
on='担当者コード'はキーをとなる列を指定します。列名が異なる場合は、left_onとright_onに分けて指定します。
how='left'は、結合の仕方を指定していますが、vlookupの場合は、mergeの左の表をベースにするからleftとすると覚えていれば問題ないです。
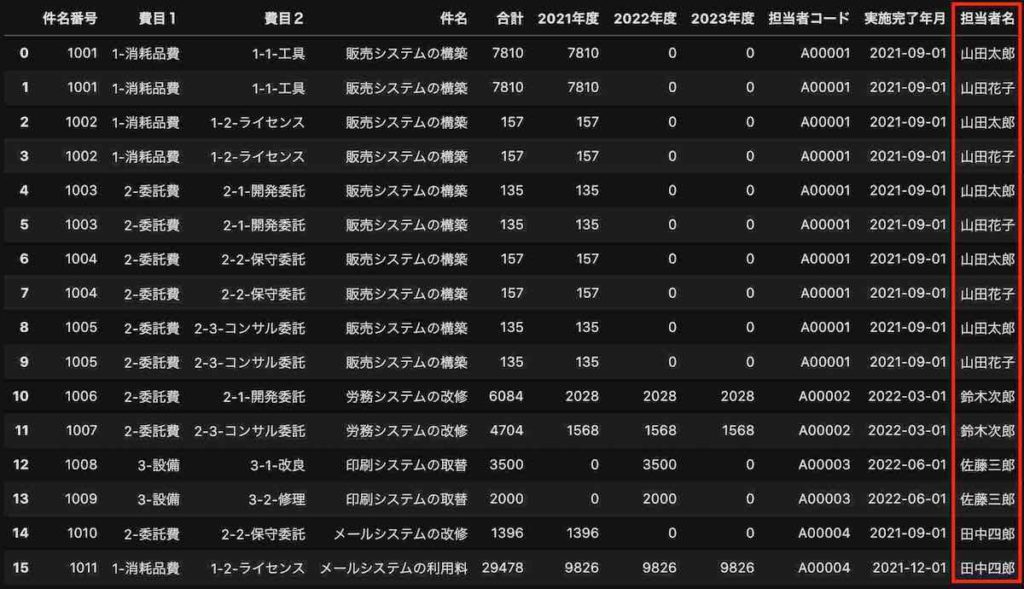
この結果は、次の通りになります。一番右の列に担当者名が追加されました。
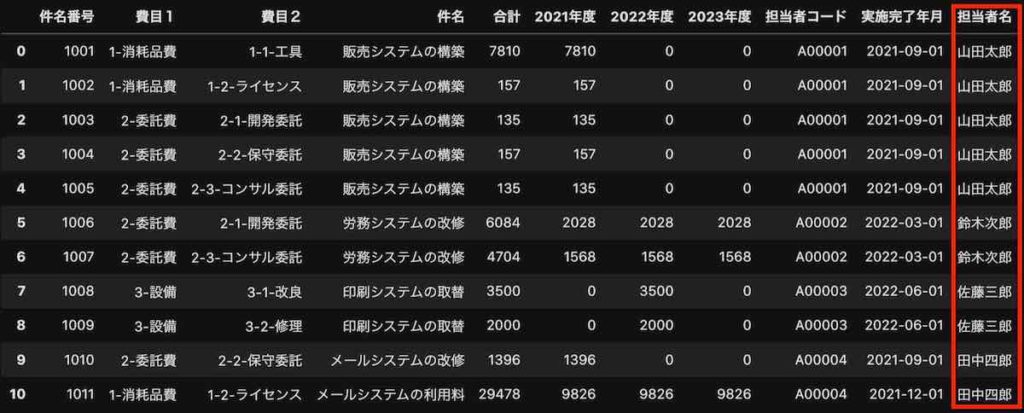

確認のため、行数と列数を確認すると、11行、11列の表になり、列が1つ追加になったのがわかります。
df.shape
#(11, 11)
PythonでExcelのVLOOKUP関数の操作を行う際の注意点
ここで、PythonでVLOOKUP的な操作を行うときの留意点を1つ紹介します。
「マスタ側の表でキーとなる列は一意にすべき」ということです。
例として、キーとなる列が一意でないマスタで処理を行ってみます。
担当者コードの「A00001」が重複しています。
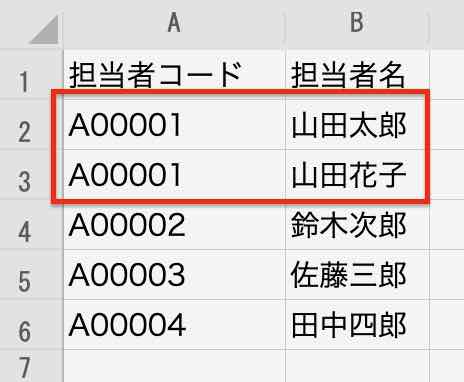

この表を「テストデータ_2.xlsx」とします。
上の処理と同様に、Excelを読み込んで、VLOOKUP的な処理を行います。
df2 = pd.read_excel('テストデータ_2.xlsx', sheet_name = '予算管理表')
df_user2 = pd.read_excel('テストデータ_2.xlsx', sheet_name = '担当者マスタ')
df2 = df2.merge(df_user2, on='担当者コード', how='left')
結果は、次の通りとなります。

df.shape
#(15, 11)
ご覧の通り、マスタで重複していた分だけレコードが増えています。
マスタのキー列に重複する値があるのを知らずに、マージすると誤って集計してしまうこともあります。
ぜひ、Pythonのmerge関数を使う時は、マスタとなる表のキーが一意であることを確認してください。
以上、PythonでExcelのVLOOKUP関数の操作を行う方法を留意点とともに説明してきました。
最後まで読んでいただき、ありがとうございました。