本記事では、Python/Pandasのgroupby関数で列のフィールド値ごとにグループ集計する方法をご紹介します。
Pythonの実行環境
今回は、以下の実行環境でプログラムを実行しています。
・Python 3.7.6
・Jupyterlab 1.2.6
・Pandas:1.1.2
テストデータは、次のような予算管理表を使います。
ファイル名は「テストデータ.xlsx」で、シート名は「予算管理表」です。
■予算管理表


本記事で、利用するライブラリはPandasです。
そして、テストデータの予算管理表をdfとして読み込んでおきます。
import pandas as pd
df = pd.read_excel('テストデータ.xlsx', sheet_name = '予算管理表')
※本記事では、Pythonのコードの下のコメントアウトは、出力結果を示しています。
Pythonで列のフィールド値ごとにグループ集計する方法(groupby)
まず、「列のフィールド値別にグループ集計」とはどういうことでしょうか。
言葉で書くよりもExcelのイメージでみた方が分かりやすいと思います。
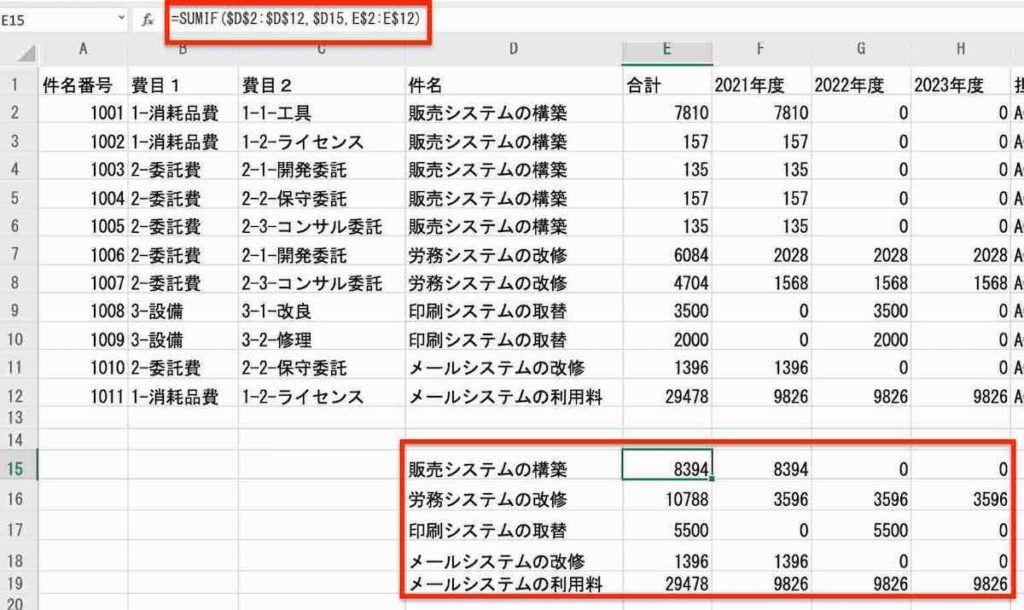

「件名」列の各フィールド値の単位で、「合計」列〜「2023年度」列の数値を合計したものとなります。
結果が、上の図の赤枠の表の部分となります。
これをPythonで行うときは、groupby()を用います。引数に、キーとなる列を指定します。
df.groupby('件名').sum()
結果は次のようになります。
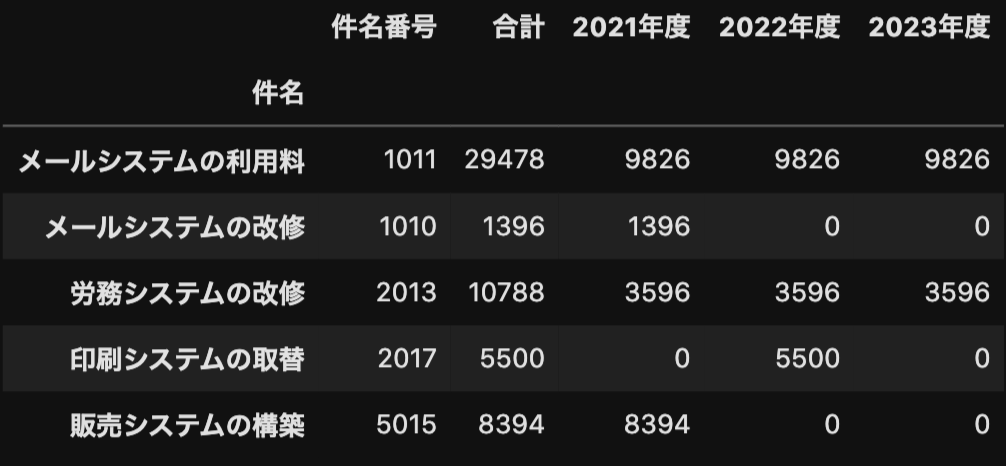

一見、よさそうに見えますが、「件名番号」列という本来不要なものまで合計されてしまっています。
これは、groupby()を使うと、数値型の列が集計されるためです。
これを防ぐには、「件名番号」列のデータ型(形式)を文字列に変更する必要があります。
Pythonで列のデータ型(形式)を変更する方法(グループ集計の準備)
テストデータとして読み込んだdfのデータ型を確認します。データ型は、dtypesで確認できます。
df.dtypes
#件名番号 int64
#費目1 object
#費目2 object
#件名 object
#合計 int64
#2021年度 int64
#2022年度 int64
#2023年度 int64
#担当者コード object
#実施完了年月 datetime64[ns]
確かに、「件名番号」列が数値型になっています。
これを変更するには、astype()を使って、次のように書きます。
df['件名番号'] = df.astype({'件名番号': 'str'})
引数には、辞書型で変更する列名と変更後のデータ方を指定します。
これで改めて、
df.groupby('件名').sum()
を行うと、結果は次の通りとなり、本来欲しい結果となりました。
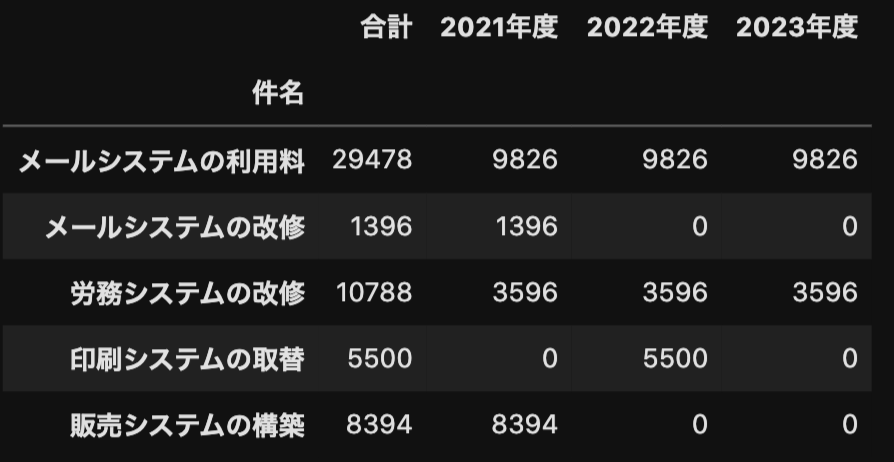

最後に、groupbyの留意点として、キーに指定した列のフィールド値の順番が指定できないということです。
上の例では、「メールシステムの利用料」→「メールシステムの改修」→・・・→「販売システムの構築」となっているのを自分の好きな並び順に指定できないということです。
(もし変更できる方法を知っている方はぜひ教えてください。)
以上、Pythonでgroupbyを使って、列のフィールド値別にグループ集計の方法を説明してきました。
最後まで読んでいただき、ありがとうございました。