ブログのキーワードを選びで、検索上位にどんな記事があるか簡単に調べたいなぁ
そんな時はPython(パイソン)でWebスクレイピングをすれば、自動で取得できるよ。


本記事では、Pythonを用いて、Google検索の上位サイトを一覧で取得する方法を紹介します。
本記事の内容
・Webスクレイピングとは
・PythonでのWebスクレイピング
・実際にPythonでWebスクレイピングをやってみたい方
Webスクレイピングとは
Webスクレイピングとは、「Webページから必要な情報を自動で抜き出す作業」です。
この作業をプログラミングで作成すれば、自動でWebから必要な情報を取得することができます。
PythonでWebスクレイピング
本記事では、PythonでのWebスクレイピングの方法をご紹介します。
実行環境
・Linux
・Python 3.7.6
Google検索上位100サイトの記事タイトルとURLを一括で取得するコード
実際のPythonのコードは、次のようになります。
下のコードでは、検索ワードを「ブログ初心者」としております。
import requests
import bs4
import pandas as pd
search_keyword = 'ブログ初心者'
print('【検索した単語】{}'.format(search_keyword))
#検索順位取得処理
#Google検索の実施
search_url = 'https://www.google.co.jp/search?hl=ja&num=100&q=' + search_keyword
res_google = requests.get(search_url)
#Responseオブジェクトが持つステータスコードが200番台(成功)以外だったら、エラーメッセージを吐き出してスクリプトを停止します。
res_google.raise_for_status()
print("Google検索結果を取得")
#res_google.textは、検索結果のページのHTML
bs4_google = bs4.BeautifulSoup(res_google.text, 'lxml')
google_search_page = bs4_google.select('div.kCrYT>a')
#rank:検索順位
rank = 1
site_rank = []
site_title = []
site_url = []
for site in google_search_page:
try:
site_title.append(site.select('h3.zBAuLc')[0].text)
site_url.append(site.get('href').split('&sa=U&')[0].replace('/url?q=', ''))
site_rank.append(rank)
rank +=1
except IndexError:
continue
print("以上")
df = pd.DataFrame({'順位':site_rank, 'タイトル':site_title, 'URL':site_url})
df.to_csv(search_keyword+'.csv', index=False)
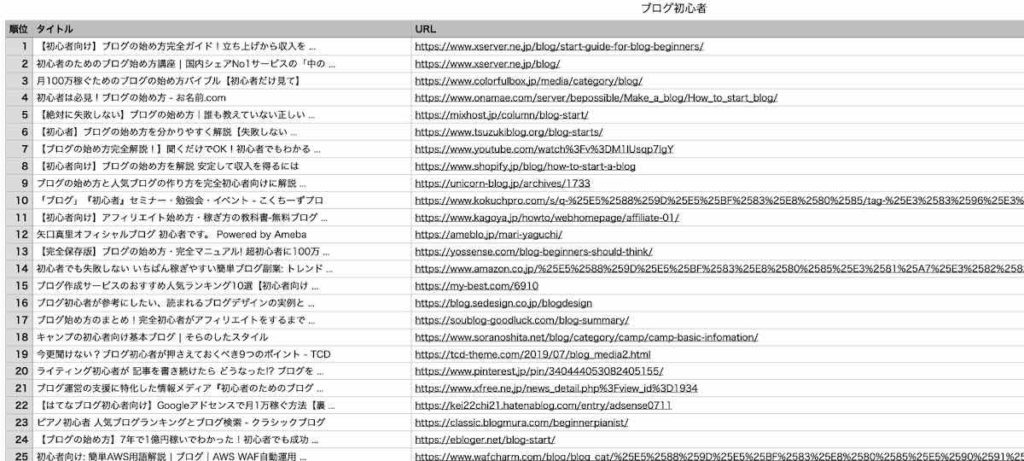
実行結果
上のソースを実行すると、下の図のようなCSVファイルが出来上がります。

実際にPythonでWebスクレイピングをやってみたい方
本記事では、Pythonを使えてば、こんな感じでGoogle検索が上位のサイトも簡単に抽出できるよ〜という紹介でした。
実際にPythonでWebスクレイピングをやってみたい方は、すぐにできるというわけではなく、まずはPythonを勉強する必要があります。。
また、ブロガーさん向けのPython勉強方法を別記事で書いていこうと思います。
Google検索上位サイトのH1, H2, H3 タグも確認したい